Loss function
In statistics and decision theory a loss function is a function that maps an event onto a real number intuitively representing some "cost" associated with the event. Typically it is used for parameter estimation, and the event in question is some function of the difference between estimated and true values for an instance of data. In the context of economics, for example, this is usually economic cost or regret. In Machine Learning, it is the penalty for an incorrect classification of an example. In Actuarial Science, it is used in an insurance context to model benefits paid over premiums.
Contents |
Definition
Formally, we begin by considering some family of distributions for a random variable X, that is indexed by some θ.
More intuitively, we can think of X as our "data", perhaps 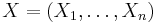 , where
, where 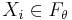 i.i.d. The X is the set of things the decision rule will be making decisions on. There exists some number of possible ways
i.i.d. The X is the set of things the decision rule will be making decisions on. There exists some number of possible ways 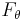 to model our data X, which our decision function can use to make decisions. For a finite number of models, we can thus think of θ as the index to this family of probability models. For an infinite family of models, it is a set of parameters to the family of distributions.
to model our data X, which our decision function can use to make decisions. For a finite number of models, we can thus think of θ as the index to this family of probability models. For an infinite family of models, it is a set of parameters to the family of distributions.
On a more practical note, it is important to understand that, while it is tempting to think of loss functions as necessarily parametric (since they seem to take θ as a "parameter"), the fact that θ is non-finite-dimensional is completely incompatible with this notion; for example, if the family of probability functions is uncountably infinite, θ indexes an uncountably infinite space.
From here, given a set A of possible actions, a decision rule is a function δ : 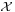 → A.
→ A.
A loss function is a real lower-bounded function L on Θ × A for some θ ∈ Θ. The value L(θ, δ(X)) is the cost of action δ(X) under parameter θ.[1]
Decision rules
A decision rule makes a choice using an optimality criterion. Some commonly used criteria are:
- Minimax: Choose the decision rule with the lowest worst loss — that is, minimize the worst-case (maximum possible) loss:
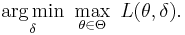
- Invariance: Choose the optimal decision rule which satisfies an invariance requirement.
- Minimize the expected value of the loss function.
Expected loss
The value of the loss function itself is a random quantity because it depends on the outcome of a random variable X. Both frequentist and Bayesian statistical theory involve making a decision based on the expected value of the loss function: however this quantity is defined differently under the two paradigms.
Frequentist risk
The expected loss in the frequentist context is obtained by taking the expected value with respect to the probability distribution, Pθ, of the observed data, X. This is also referred to as the risk function[2] of the decision rule δ and the parameter θ. Here the decision rule depends on the outcome of X. The risk function is given by
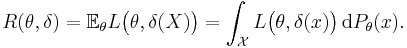
Bayesian expected loss
In a Bayesian approach, the expectation is calculated using the posterior distribution π* of the parameter θ:
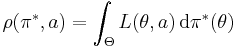 .
.
One then should choose the action a* which minimises the expected loss. Although this will result in choosing the same action as would be chosen using the Bayes risk, the emphasis of the Bayesian approach is that one is only interested in choosing the optimal action under the actual observed data, whereas choosing the actual Bayes optimal decision rule, which is a function of all possible observations, is a much more difficult problem.
Selecting a loss function
Sound statistical practice requires selecting an estimator consistent with the actual loss experienced in the context of a particular applied problem. Thus, in the applied use of loss functions, selecting which statistical method to use to model an applied problem depends on knowing the losses that will be experienced from being wrong under the problem's particular circumstances, which results in the introduction of an element of teleology into problems of scientific decision-making.
A common example involves estimating "location." Under typical statistical assumptions, the mean or average is the statistic for estimating location that minimizes the expected loss experienced under the Taguchi or squared-error loss function, while the median is the estimator that minimizes expected loss experienced under the absolute-difference loss function. Still different estimators would be optimal under other, less common circumstances.
In economics, when an agent is risk neutral, the loss function is simply expressed in monetary terms, such as profit, income, or end-of-period wealth.
But for risk averse (or risk-loving) agents, loss is measured as the negative of a utility function, which represents satisfaction and is usually interpreted in ordinal terms rather than in cardinal (absolute) terms.
Other measures of cost are possible, for example mortality or morbidity in the field of public health or safety engineering.
For most optimization algorithms, it is desirable to have a loss function that is globally continuous and differentiable.
Two very commonly-used loss functions are the squared loss, 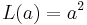 , and the absolute loss,
, and the absolute loss, 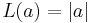 . However the absolute loss has the disadvantage that it is not differentiable around
. However the absolute loss has the disadvantage that it is not differentiable around 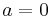 . The squared loss has the disadvantage that it has the tendency to be dominated by outliers---when summing over a set of
. The squared loss has the disadvantage that it has the tendency to be dominated by outliers---when summing over a set of 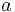 's (as in
's (as in 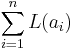 ), the final sum tends to be the result of a few particularly-large a-values, rather than an expression of the average a-value.
), the final sum tends to be the result of a few particularly-large a-values, rather than an expression of the average a-value.
Loss functions in Bayesian statistics
One of the consequences of Bayesian inference is that in addition to experimental data, the loss function does not in itself wholly determine a decision. What is important is the relationship between the loss function and the prior probability. So it is possible to have two different loss functions which lead to the same decision when the prior probability distributions associated with each compensate for the details of each loss function.
Combining the three elements of the prior probability, the data, and the loss function then allows decisions to be based on maximizing the subjective expected utility, a concept introduced by Leonard J. Savage.
Regret
Savage also argued that using non-Bayesian methods such as minimax, the loss function should be based on the idea of regret, i.e., the loss associated with a decision should be the difference between the consequences of the best decision that could have been taken had the underlying circumstances been known and the decision that was in fact taken before they were known.
Quadratic loss function
The use of a quadratic loss function is common, for example when using least squares techniques or Taguchi methods. It is often more mathematically tractable than other loss functions because of the properties of variances, as well as being symmetric: an error above the target causes the same loss as the same magnitude of error below the target. If the target is t, then a quadratic loss function is
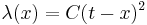
for some constant C; the value of the constant makes no difference to a decision, and can be ignored by setting it equal to 1.
Many common statistics, including t-tests, regression models, design of experiments, and much else, use least squares Linear models theory, which is based on the Taguchi loss function.
The quadratic loss function is also used in linear-quadratic optimal control problems.
See also
References
- ^ Nikulin, M.S. (2001), "Loss function", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1556080104, http://www.encyclopediaofmath.org/index.php?title=L/l060900
- ^ Nikulin, M.S. (2001), "Risk of a statistical procedure", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1556080104, http://www.encyclopediaofmath.org/index.php?title=R/r082490
Further reading
- Berger, James O. (1985). Statistical decision theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. ISBN 0-387-96098-8. MR0804611.